Go back
How I built my blog with Next.js and MDX
Apr 21, 2022 · 22 min read
When I was building this blog, a lot of tools that I could use to achieve this were readily available. From tools like, Gastby, Content Management Systems (CMS) like Ghost, Contentful, Sanity dot io, HUGO etc.
But I needed something that I can have total control of, and I've always been someone that loves the flexibility that writing my custom code brings because I can conveniently go back to where the issue might be coming from when a problem arises.
Although Gatsby provides this flexibility, and it is something that I might be familiar with since it is a tool that is built on a library (React.js) I use every day. But, I found out that I can do the exact same thing with Next.js by integrating MDX. "What is MDX?" You might ask me.
Well... MDX is more or less like the markdown files we always see in Github repositories. MDX brings this flexibility into a markdown file by allowing you to literally write or import Javascript (React) components into your articles, which in turn saves you from writing code in a repetitive manner.
In this article, I am going to show you how I built this blog with the tools I used, so you can also try building something similar if you are a person that loves the flexibility that this approach brings. So, sit tight, and let's get started.
The Drawbacks and travails 😢
To build a blog with Next.js and MDX, there are four popular options that you can choose from.
They are:
- @next/mdx, the official tool built by the Next.js team
- Kent C. Dodds' mdx-bundler
- next-mdx-remote, a tool built by the Hashicorp team
- next-mdx-enhanced a tool also built by Hashicorp (I honestly don't know why they decided to build two)
At first, I started by using Kent's mdx-bundler, but then I ran into a lot of problems with the tool, as it is a library that is based on the new ECMAScript standards that allow us to create ESModules in the browser, and I was using a very old version of Next.js (V10.1.3, my bad honestly, I didn't know any better).
I did a lot of downgrading and upgrading of Next.js to fix this problem to no avail. There was a certain error that stuck with me, and refused to go, for days!! Yes, for days! I felt like crying during that period. Take a look at the error below;
Apparently, for mdx-bundler to work, it needs another npm package called esbuild, to do the necessary compiling processes that works under the hood.
npm i mdx-bundler esbuildLuckily for me — at least I thought I was lucky — Cody Brunner submitted an issue about this particular error. Going through the discussions on the issue, a lot of possible fixes were suggested, some of them were related to webpack, modifying your next.config.js file, and whatnot.
module.exports = {
future: {
// Opt-in to webpack@5
webpack5: true,
},
reactStrictMode: true,
webpack: (config, { buildId, dev, isServer, defaultLoaders, webpack }) => {
if (!isServer) {
// https://github.com/vercel/next.js/issues/7755
config.resolve = {
...config.resolve,
fallback: {
...config.resolve.fallback,
child_process: false,
fs: false,
'builtin-modules': false,
worker_threads: false,
},
}
}
return config
},
}In the snippet above, it shows that webpack5 was still a feature that was in progress for Next.js hence the snippet below in the config
future: {
webpack5: true
}But, now the latest version of Next.js supports webpack5 by default, so there's no need to add that object — if it works for you — in the config. After going through the discussions, I found a comment — by Kent — that says running npm update would fix the issue, and it did work for Cody Brunner, but not for me apparently.
When I couldn't find a possible fix to this error, I decided to use next-mdx-remote, and the only issue I faced was the breaking change that was added to the tool. Before version 3 of next-mdx-remote you would normally render parsed markdown content by doing the following;
import renderToString from 'next-mdx-remote/render-to-string'
import hydrate from 'next-mdx-remote/hydrate'
import Test from '../components/test'
export default function TestPage({ source }) {
const content = hydrate(source, { components })
return <div className="content">{content}</div>
}
export async function getStaticProps() {
// MDX text - can be from a local file, database, anywhere
const source = 'Some **mdx** text, with a component <Test />'
const mdxSource = await renderToString(source, { components })
return {
props: {
source: mdxSource,
},
}
}The breaking change that was added in version 3 of the package stripped off a lot of internal code that was perceived to cause poor experiences for people who were using it at that time.
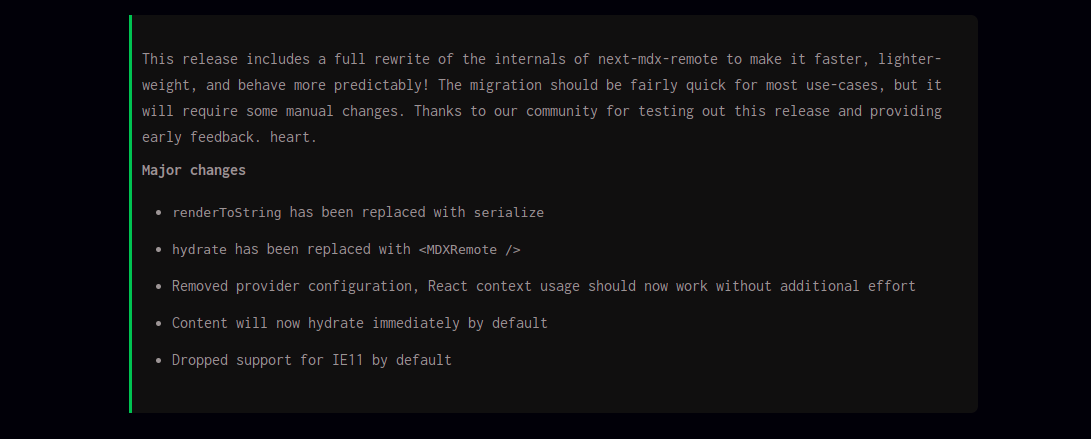
The team went on to announce the reason behind this change and the major changes. Take a look at them below.
This release includes a full rewrite of the internals of next-mdx-remote to make it faster, lighter-weight, and behave more predictably! The migration should be fairly quick for most use-cases, but it will require some manual changes. Thanks to our community for testing out this release and providing early feedback. heart.
Major changes
renderToStringhas been replaced withserializehydratehas been replaced with<MDXRemote />- Removed provider configuration, React context usage should now work without additional effort
- Content will now hydrate immediately by default
- Dropped support for IE11 by default
With this new change, the preveious implementation will now become:
import { serialize } from 'next-mdx-remote/serialize'
import { MDXRemote } from 'next-mdx-remote'
import { Test, Image, CodeBlock } from '../components/'
const components = { Test }
export default function TestPage({ source }) {
return (
<div className="content">
<MDXRemote {...source} components={{ Test, Image, CodeBlock }} />
</div>
)
}
export async function getStaticProps() {
// MDX text - can be from a local file, database, anywhere
const source = 'Some **mdx** text, with a component <Test />'
const mdxSource = await serialize(source)
return {
props: {
source: mdxSource,
},
}
}Building the blog
In the previous section, I walked you through some of the issues I encountered while I was choosing a suitable tool to use. In this section, we're going to cover how you can build a similar blog like mine.
We'll start by creating a Next.js app with the command below
npx create-next-app blogThe command above will give you a boilerplate of a typical Next.js app. For the sake of brevity, I'll be focusing more on the pages and src/utils folder of this app.
.
├── pages/
│ ├── blog/
│ │ ├── index.js
│ │ └── [slug].js
│ ├── _app.js
│ └── index.js
├── src/
│ └── utils/
│ └── mdx.js
└── data/
└── articles/
├── example-post.mdx
└── example-post2.mdxIn a typical blog, we'd need to write blog posts or articles. In this blog, we're using markdown (MDX) to write our articles, that's why you can see that we have two .mdx files inside the data/articles directory. You can have more than that, as far as the number of articles you want to write goes.
Reading the markdown (MDX) files
In this section, we're going to start by writing some reusable functions inside src/utils/mdx.js. The functions we're writing here will be making use of Node.js' FileSystem API, and we'll be calling the functions at the server-side in the pages folder because Next.js has some data-fetching methods that runs on the server.
Let's start by installing the dependencies that we need for now. As we progress, we'll be adding other dependencies
npm install gray-matter reading-time next-mdx-remote glob dayjsThe command above will get all packages listed above, as dependencies in our blog project.
gray-matter will parse the content in the .mdx files to readable HTML content.
reading-time assigns an approximate time to read a blog post or article based on the word count.
next-mdx-remote does the background compilation of the MDX files by allowing them to be loaded within Next.js' getStaticProps or getServerSideProps data-fetching method, and hydrated properly on the client.
glob gives us access to match the file patterns in data/articles, which we'll be using as the slug of the article.
dayjs is a JavaScript library that helps to parse, manipulate, validate, and display dates that we would be adding to the metadata of each article.
We've seen the basic functions, of the packages we installed. Now let's start writing the functions that'll read the files in the articles directory.
import path from 'path'
import fs from 'fs'
import matter from 'gray-matter'
import readingTime from 'reading-time'
import { sync } from 'glob'
const articlesPath = path.join(process.cwd(), 'data/articles')
export async function getSlug() {
const paths = sync(`${articlesPath}/*.mdx`)
return paths.map((path) => {
// holds the paths to the directory of the article
const pathContent = path.split('/')
const fileName = pathContent[pathContent.length - 1]
const [slug, _extension] = fileName.split('.')
return slug
})
}In the snippet above, we've imported the Node.js FileSystem from its module and the other packages. The first variable declaration, articlesPath holds the path to where all the articles can be found.
const articlesPath = path.join(process.cwd(), 'data/articles')We're using the path module to get access to where the articles are by tapping into the process API of Node.js which gives us direct access to the cwd() (Current Working Directory) object.
The getSlug function will get a unique article, when it is clicked upon, by the user
on the blog page. You'll see that we're referencing the articlesPath variable that was declared before, and we're passing it to the sync function of the glob package, which will in turn match any file that has the .mdx extension, and give us an array with a list of these files
const paths = sync(`${articlesPath}/*.mdx`)With that being said, we'll return an array of modified file names. The pathContent variable holds the path to all the articles in the articles directory, so we're using JavaScript to remove all the "forward-slashes" with the split() method of JavaScript.
const fileName = pathContent[pathContent.length - 1]
const [slug, _extension] = fileName.split('.')The fileName variable declaration gets the last part of path, say for example "/data/articles/example-post.mdx", since it is an array, and returns the last part which is /example-post.mdx. The next variable goes on to remove the period (.) from the filename itself, so we'll be left with example-post as the slug.
Parse article content from the slug
The next function gets, and parses the content in our MDX files from the slugs and returns an object of metadata that we'll be using as we progress.
export async function getArticleFromSlug(slug) {
const articleDir = path.join(articlesPath, `${slug}.mdx`)
const source = fs.readFileSync(articleDir)
const { content, data } = matter(source)
return {
content,
frontmatter: {
slug,
excerpt: data.excerpt,
title: data.title,
publishedAt: data.publishedAt,
readingTime: readingTime(source).text,
...data,
},
}
}In the snippet above, we're using Node.js' readFileSync function from the FileSystem API to read the files in the articleDir in a synchronous manner. What we're doing with this function — readFileSync — is, we're telling Node to stop other processes that are currently going on, and perform this operation for us.
You can learn more about it here, if you want to.
If you go ahead and console.log(source) in your terminal, you'll get a <Buffer> — which isn't readable — data type in your console. This is where the gray-matter package comes to save the day. It helps in parsing the markdown content in the source to something — readble HTML — that you and I can understand.
Here, we're destructuring content and data variables, assigning it to the matter package, which parses the source, and returns an object that holds our content and frontmatter: data variables
const { content, data } = matter(source)
return {
content,
frontmatter: {
slug,
excerpt: data.excerpt,
title: data.title,
publishedAt: data.publishedAt,
readingTime: readingTime(source).text,
...data,
},
}We need a way to display all the articles on the blog page. The function below does that for us, by utilizing the reduce() method of JavaScript to return an array of all the articles in the articles directory.
export async function getAllArticles() {
const articles = fs.readdirSync(path.join(process.cwd(), 'data/articles'))
return articles.reduce((allArticles, articleSlug) => {
// get parsed data from mdx files in the "articles" dir
const source = fs.readFileSync(
path.join(process.cwd(), 'data/articles', articleSlug),
'utf-8'
)
const { data } = matter(source)
return [
{
...data,
slug: articleSlug.replace('.mdx', ''),
readingTime: readingTime(source).text,
},
...allArticles,
]
}, [])
}You can see how we're using readdirSync() to synchronously read all the files inside data/articles. The source variable can be accessed by reading all the files with their respective slugs and get their content parsed with the gray-matter package
const source = fs.readFileSync(
path.join(process.cwd(), 'data/articles', articleSlug),
'utf-8'
)
const { data } = matter(source)If you take a look at the snippet below, you'll see how we're using the reading-time package to get the approximate time it will take to read this article, and the slug that will be attached to this article stripping the last part of the article — blog/example-post.mdx — and replacing it with an empty string, thus making accessible via "blog/example-post"
{
slug: articleSlug.replace('.mdx', ''),
readingTime: readingTime(source).text,
}The readingTime has some methods that you can assign to it, one of them is the text method. You can try removing this value, save your code and allow Next.js to throw an error, so you can get a glimpse of the values that you can use.
Displaying a list of articles
In the previous sections, we have seen how we can use the Node.js FileSystem API and a couple of other tools to get access to where all our articles are. In this section, we'll be displaying the articles on a webpage.
We'll start with the index file in the blog folder. In this file, we'll be using the data-fetching method — getStaticProps — to render the articles on the page.
import { getAllArticles } from '../../src/utils/mdx'
export async function getStaticProps() {
const articles = await getAllArticles()
articles
.map((article) => article.data)
.sort((a, b) => {
if (a.data.publishedAt > b.data.publishedAt) return 1
if (a.data.publishedAt < b.data.publishedAt) return -1
return 0
})
return {
props: {
posts: articles.reverse(),
},
}
}In the snippet above, we imported the getAllArticles function and used it in the data-fetching method of Next.js. You'll notice how we're sorting the articles based on the date that it was published, and we'd eventually map the list of articles that will be returned as props to the index (blog) page.
articles
.map((article) => article.data)
.sort((a, b) => {
if new Date(a.data.publishedAt) > new Date(b.data.publishedAt) return 1
if new Date (a.data.publishedAt) < new Date(b.data.publishedAt) return -1
return 0
})Lest I forget, this is how the content of your typical article file will look in markdown syntax below;
---
title: 'Next.js Image optimization error on Netlify'
publishedAt: '2022-04-16'
excerpt: 'Next.js has a built-in Image component that comes with a lot of performance optimization features when you are using it.'
cover_image: 'path/to/where/image/is/stored'
---
rest of the content falls hereYou may ask me, "why do we need to sort the articles by date if we can just use the reverse() method to re-order the array of articles?". I think it is appropriate for us to sort the list of articles by comparing them with the date they were published and still apply the reverse method to the array.
Say, for example, we forget to add the published dates to the articles, the reverse() method will just perform the operation on the array without comparing the dates in a LIFO — Last-In-First-Out — pattern, if the sort function is missing. So it is better to sort the articles and still reverse the content of the array.
Now that we've returned the list of articles as props we can go ahead to map them onto the page.
import React from 'react'
import Head from 'next/head'
import Link from "next/link"
import { getAllArticles } from '../../src/utils/mdx'
export default function BlogPage({ posts }) {
return (
<React.Fragment>
<Head>
<title>My Blog</title>
</Head>
<div>
{posts.map((frontMatter) => {
return (
<Link href={`/blog/${frontMatter.slug}`} passHref>
<div>
<h1 className="title">{frontMatter.title}</h1>
<p className="summary">{frontMatter.excerpt}</p>
<p className="date">
{dayjs(frontMatter.publishedAt).format('MMMM D, YYYY')} —{' '}
{frontMatter.readingTime}
</p>
</div>
</Link>
)
})}
</div>
</React.Fragment>
)
}
export async function getStaticProps() {
...
}In the snippet above we're using the Link component to route the user to a dynamic page with the unique article's slug. This is the reason we created a file called [slug].js, if you can recall. It is a dynamic route, and read more about it here
Displaying a unique article
In the last section, we were able to render the list of articles onto the webpage. In this section, we'll be rendering a unique article that gets clicked on, by the user in a new route.
We're also going to be using a tool called rehype to customize what our blog post will look like. Rehype is an HTML pre-processor that is powered by plugins. We'll be using some of these plugins in this section, so let's install them now.
npm i rehype-highlight rehype-autolink-headings rehype-code-titles rehype-slugrehype-highlight allows us to add syntax highlighting to our code blocks
rehype-autolink-headings is a plugin that adds links to headings from h1 to h6
rehype-code-titles adds language/file titles to your code
rehype-slug is a plugin that adds an id attributes to headings
Now that we've seen the roles that each plugin carries out, let's start working on the [slug].js file. In this file, we'll be using two data-fetching methods of Next.js — getStaticProps and getStaticPaths` —.
We're using these two methods because we'd be fetching data (articles) that is unique to the path (slugs) that the user is redirected to.
// dynamically generate the slugs for each article(s)
export async function getStaticPaths() {
// getting all paths of each article as an array of
// objects with their unique slugs
const paths = (await getSlug()).map((slug) => ({ params: { slug } }))
return {
paths,
// in situations where you try to access a path
// that does not exist. it'll return a 404 page
fallback: false,
}
}When you take a look at the snippet above, you'll see that we're obtaining the list of paths from the articles, and mapping that list of items (paths) to an array, which can be accessed with the params variable in the getStaticProps data-fetching method.
import { getArticleFromSlug } from "../../src/utils/mdx"
export async function getStaticProps({ params }) {
//fetch the particular file based on the slug
const { slug } = params
const { content, frontmatter } = await getArticleFromSlug(slug)
const mdxSource = await serialize(content, {
mdxOptions: {
rehypePlugins: [
rehypeSlug,
[
rehypeAutolinkHeadings,
{
properties: { className: ['anchor'] },
},
{ behaviour: 'wrap' },
],
rehypeHighlight,
rehypeCodeTitles,
],
},
})
return {
props: {
post: {
source: mdxSource,
frontmatter,
},
},
}
}`In the snippet above, we're destructuring content and frontmatter — which is the metadata of the article — and assigning it to the getArticleFromSlug function which receives the slug of the article as an argument.
We continued by serializing the content of the article with next-mdx-remote's serialize() function, and pass the necessary rehype plugins in the mdxOptions object
const mdxSource = await serialize(content, {
mdxOptions: {
rehypePlugins: [
rehypeSlug,
[
rehypeAutolinkHeadings,
{
properties: { className: ['anchor'] },
},
{ behaviour: 'wrap' },
],
rehypeHighlight,
rehypeCodeTitles,
],
},
})To wrap it up, we return the content of the article and the frontmatter as props that'll be accessed by the slug component.
return {
props: {
post: {
source: mdxSource,
frontmatter,
},
},
}The props that we returned in the previous snippets can be accessed via the component below. You'll notice that the <MDXRemote /> component receives the {...source} and custom React component props that we can use in our MDX files. This eradicates the process of having to write repetitive code over and over.
import dayjs from 'dayjs'
import React from 'react'
import Head from 'next/head'
import Image from 'next/image'
import rehypeSlug from 'rehype-slug'
import { MDXRemote } from 'next-mdx-remote'
import rehypeHighlight from 'rehype-highlight'
import rehypeCodeTitles from 'rehype-code-titles'
import { serialize } from 'next-mdx-remote/serialize'
import 'highlight.js/styles/atom-one-dark-reasonable.css'
import rehypeAutolinkHeadings from 'rehype-autolink-headings'
import { getSlug, getArticleFromSlug } from '../../src/utils/mdx'
import { SectionTitle, Text } from '../../data/components/mdx-components'
export default function Blog({ post: { source, frontmatter } }) {
return (
<React.Fragment>
<Head>
<title>{frontmatter.title} | My blog</title>
</Head>
<div className="article-container">
<h1 className="article-title">{frontmatter.title}</h1>
<p className="publish-date">
{dayjs(frontmatter.publishedAt).format('MMMM D, YYYY')} —{' '}
{frontmatter.readingTime}
</p>
<div className="content">
<MDXRemote {...source} components={{ Image, SectionTitle, Text }} />
</div>
</div>
</React.Fragment>
)
}In the snippet above, you'll notice how we destructured the post props into { source, frontmatter }, so instead of doing this, in the <MDXRemote> component below, we can just spread the source variable directly as a prop.
<MDXRemote {...post.source} />Notice how we're also dynamically rendering the title of the page with the title of the article instead of the normal title? This is gotten from the frontmatter.
<Head>
<title>{frontmatter.title} | My blog</title>
</Head>Final thoughts
Every developer definitely loves having their fancy themes applied to their editors, this isn't also left out in this blog. I'm currently using the "atom-one-dark-reasonable" theme for my syntax highlighting. It can be imported from the "highlight.js" library — since the rehype-highlight plugin uses it under the hood — below;
import 'highlight.js/styles/atom-one-dark-reasonable.css'There are a lot of other themes here, you can choose anyone that you're comfortable with.
You'd have noticed — while reading this article — that there are some components like the one in the image below, and you may have been wondering how it was created.
You can decide to have a lot of custom MDX components that you can use in your articles. But, I decided to target any element that I want to style in this article by assigning a generic className to it. So whenever I want to use it, I just reference that style in the element.
SEO is one of the important things when it comes to building a blog, and luckily for us, Next.js already has that covered for us. You can take a look at this article that walks you through How to add SEO Meta tags in your Next.js apps and How I fixed a meta tag pre-rendering error in Next.js
There is an important thing that you must not forget, and that is the next.config.js file. You need to make sure that it is properly set up so you can avoid one of the version compatibility errors of the latest version of React — v18.0.0 — with next-mdx-remote.
Although the Hashicorp team said they've fixed this in their latest release, it didn't work for me. A way to bypass this error is to install next-mdx-remote as a legacy peer dependency, like so;
npm i next-mdx-remote --legacy-peer-depsAnd make sure to have a next.config file that looks like what you're seeing below.
module.exports = {
reactStrictMode: true,
images: {
loader: 'akamai',
path: '',
},
webpack: (config) => {
config.resolve.alias = {
...config.resolve.alias,
'react/jsx-runtime.js': require.resolve('react/jsx-runtime'),
}
config.resolve = {
...config.resolve,
fallback: {
...config.resolve.fallback,
child_process: false,
fs: false,
// 'builtin-modules': false,
// worker_threads: false,
},
}
return config
},
}The resolve.alias object in the config above helps as a workaround in fixing the error below
Server error
Error: Package subpath "./jsx-runtime.js" is not defined by "exports" in "path-to-node_modules/react/package.json"
Sometimes you may also encounter an error that has to do with the "builtin" modules of Node.js while you're deploying your project. The config.resolve object with the fallback key helps in removing that error.
You'll notice that there's an image object in the config.
images: {
loader: 'akamai',
path: '',
},Its role is to ensure that the proper Image optimization process is used during the build process. You can take a look at an article I wrote about how you can fix the Next.js Image optimization error on Netlify
Update
In the section that required us to sort the articles based on the date that they were published. We had to use the sort method to compare the dates and later on we passed the .reverse() to it too.
Looking at my blog now, I realized that the implementation was a little bit off, So here's the one that'll help you sort the articles based on the dates that they were published with the Date() constructor in JavaScript.
let articles = await getAllArticles()
const sortedArticles = articles.map((article) => article)
sortedArticles.sort((a, b) => {
return new Date(b.publishedAt) - new Date(a.publishedAt)
})
return {
props: {
posts: sortedArticles,
},
}Thank you so much for reading this article, I hope you find it helpful.